Серпом по ссылкам
Расширение для Chromium, извлекающее ссылки из результатов поиска Яндекса, Гугла и даже Бинга
Описание
Сей скрипт предназначен для сбора ссылок из результатов поиска Яндекса и Google. Ссылки собираются в элемент textarea, который добавляется под результаты выдачи. Писался изначально для себя. Сейчас скрипт превратился в то, что не стыдно показать людям. На самом деле технически скриптов два (один - для Яндекса, другой - для Гугла). Так как они решают одну и ту же задачу, просто в разных поисковых системах, я счел логичным разместить их на одной странице. Будем считать, что это два модуля одного и того же скрипта, парсящего ссылки.
Особенности модуля для Яндекса такие.
- Скрипт осуществляет сбор ссылок из результатов веб-поиска, поиска по людям, поиска по блогам, из Яндекс.Каталога (пока он был жив), из списка дубликатов в поиске по картинкам (в последнем случае собираются ссылки на графические файлы), а также из поиска в Яндекс.Новостях.
- Извлечение ссылок реализовано в виде универсальной функции, что облегчает расширение области функционирования скрипта. Добавить сбор ссылок из результатов поисковых сервисов Яндекса, с которыми скрипт пока не работает, относительно легко. Также есть возможность извлекать из одной страницы разные типы ссылок с разными классами, в таком случае появляется несколько элементов textarea один под другим. В разумных пределах ограничений на количество нет.
- Ширина элемента с извлеченными ссылками берется из значения ширины формы для ввода запроса (текстовое поле с желтой стрелкой). Для картинок элемент делается чуть пошире. Впрочем, элемент textarea хорош тем, что его можно легко растянуть мышкой до комфортного размера.
- Имеется статистика для дополнительного контроля. Скрипт пишет, сколько ссылок нашел вообще, сколько извлек, сколько отфильтровал. Не должны извлекаться ссылки с рекламой (Директ) и колдунщики Яндекса. Если, например, в настройках поиска Яндекса прописано показывать по 50 результатов на странице, а скрипт извлек 51 - стоит сообщить автору (то есть мне): видимо, попало что-то лишнее. Если же нужно получить 50, а извлечено 49 - возможно, в выдаче имеется колдунщик, который скрипт справедливо проигнорировал. Ежели колдунщика таки нет - надо показать автору: вероятно, что-то лишнее отфильтровалось (если, конечно, результатов вообще больше 49).
- Имеется кнопочка для выделения и копирования ссылок в буфер обмена. Извещение об успешности копирования имеется. В некоторых старых браузерах копирование может не сработать, но выделение, по идее, сработать должно; в подобных случаях можно скопировать выделенное старой доброй комбинацией клавиш Ctrl и С. Если надо скопировать только одну-две ссылки, придется выделять вручную и задействовать те же клавиши Ctrl и С.
- Скрипт проявляет признаки разума при ошибках. При отсутствии класса для парсинга (если у Яндекса, сменится верстка, класс ссылок будет переименован, и скрипт его уже не найдет) скрипт положит соответствующее сообщение в элемент textarea вместо ссылок. При отсутствии класса, после коего надо прицепить элемент со ссылками, скрипт прицепит элемент просто в самый-самый конец страницы. Можно было бы сделать такое поведение по умолчанию (в первых версиях скрипта так и было), но это может быть не самым лучшим решением, если подвал большой. Поэтому сейчас скрипт добавляет элемент со ссылками по возможности перед подвалом.
- В названии скрипта «Серпом по ссылкам» заключен
глубокий философскийсмысл. Во-первых, это намек на аббревиатуру SERP. Во-вторых, серп - острая штука, которой удобно что-либо вырезать (в данном случае ссылки). В-третьих, есть такое выражение «как серпом по яйцам». :)
Особенности модуля для Google такие.
- Скрипт осуществляет сбор ссылок из результатов веб-поиска и из результатов поиска по картинке (на самом деле там просто идентичная верстка).
- Ширина элемента с извлеченными ссылками вычисляется на основе ширины блока с найденным (это блок со ссылками и сниппетами) в самом Гугле.
- Элемент со ссылками добавляется сразу после навигации по страницам выдачи, а если блок с навигацией не найден - в самый низ страницы.
- Статистика имеется. Обычно ссылок 10. Если меньше - скорее всего, в результаты попало нечто, не имеющее отношения к органической выдаче, что собирать не кажется чем-то полезным.
- Кнопка выделения и копирования с извещением о результате тоже имеется.
Особенности модуля для Bing такие.
- Скрипт осуществляет сбор ссылок из результатов веб-поиска.
- Ширина элемента с извлеченными ссылками вычисляется на основе ширины блока с найденным в выдаче Бинга.
- Элемент со ссылками добавляется сразу после навигации по страницам выдачи, а если блок с навигацией не найден - в самый низ страницы.
- Статистика (количество извлеченных ссылок) - есть.
- Кнопка выделения и копирования с извещением о результате - есть.
Багрепорты принимаются на почту, которую можно найти в подвале.
Установка
Инструкция по установке в Chromium есть в разделе с кромешностями.
На самом деле внутри два автономных UserJS (один скрипт для Яндекса, другой - для Гугла), так что можно распотрошить дополнение, и задействовать любой из скриптов отдельно - как обычный UserJS (например, через расширение Tampermonkey или иное подобное). Писались скрипты в разное время, чем объясняются некоторые отличия во внешнем виде. Объединение их в одно расширение позволяет не зависеть от сторонних дополнений, запускающих UserJS.
После успешной установки под результатами поиска станет появляться что-то такое:
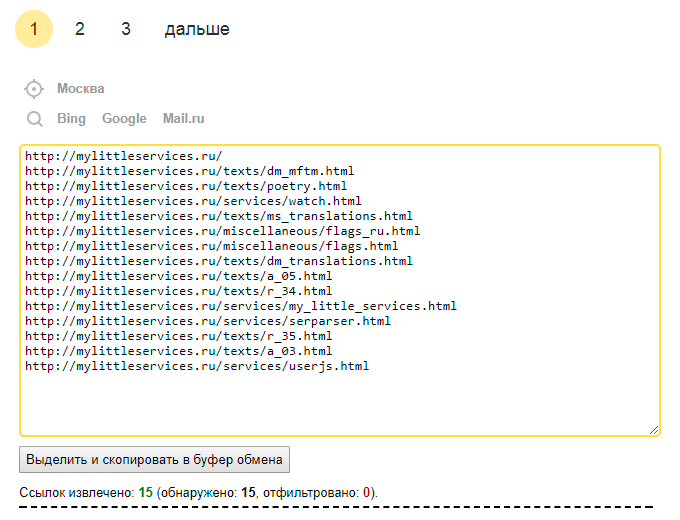
Руководство пользователя
Что нужно иметь в виду.
- Верстка Яндекса и Гугла меняется периодически. Если у классов изменятся имена, скрипт перестает их узнавать. В таком случае скрипт сообщит, что его нужно обновить. Если самостоятельно никак (на самом деле это несложно: скрипт можно править в любом текстовом редакторе; актуальный класс можно найти, открыв исходный код страницы результатов), а я торможу - стоит написать мне письмо.
- Надо держать в уме особенность расширений: обычно они отрабатывают 1 (один) раз после загрузки страницы. Это означает, что динамически измененные данные скрипт уже не увидит и, конечно, не обработает. При отсутствии элемента со ссылками, равно как и при отсутствии изменений в списке ссылок при переходе на следующую страницу выдачи, первым делом нужно
истерично долбить по клавише F5 полминутыобновить страницу в браузере: возможно, результаты подгрузились динамически. - Дубликаты изображений в поиске по картинкам Яндекса почти всегда подгружаются динамически, в связи с чем без дополнительных действий извлекается только часть ссылок. Победить беду сию можно вполне: для этого в поиске по картинкам скрипт отрабатывает с задержкой.
Порядок действий такой.- Открыть страницу с дубликатами (настоятельно рекомендую открывать ее в новой вкладке).
- Счетчик начинает обратный отсчет.
- Прокрутить страницу с дубликатами в самый низ, чтобы подгрузились все копии.
- Отсчет заканчивается, скрипт отрабатывает и извлекает все ссылки, которые подгрузились.
Журнал версий
My Little SERParser 3.6
- У Гугла снова изменилась верстка. На сей раз выкатили бесконечную выдачу. Ну, не бесконечную, конечно, но разделения на страницы более нет. Яндекс такое пробовал много лет назад, и эксперименты показали негативное отношение пользователей. Штош, Гугл о пользователях вряд ли будет думать, так что с мутными простынями придется жить. Парсер отныне фиксирует результат в левом углу экрана, ибо подвала у Гугла по сути более нет. Извлечение ссылок идет более грубо, туда могут попадать и колдунщики, и метадокументы, и много что еще - но ковыряться в исходном месиве Гугла неохота.
- В связи с предыдущим пунктом возникла проблемка: довольно большую часть экрана теперь занимает блок с результатами извлечения ссылок. Покуда сделал просто кнопочку удаления всего блока.
- У Яндекса проскальзывают иногда новые названия для классов в верстке. Добавил их на всякий случай в парсинг.
My Little SERParser 3.5
- Подключена работа в домене ya.ru.
- Добавлена иконка размером 16 пикселей.
My Little SERParser 3.4
- Сызнова некультяпистая верстка Гугла выявлена, в связи с чем мог теряться первый документ. Подправил скрипт для Гугла. Не особо надежно, но теперь скорее выудится лишнее (метадокументы), нежели потеряется нужное.
My Little SERParser 3.3
- Небольшая корректировка показа сообщения о нулевом количестве извлеченных ссылок. Теперь это место работает более правильно.
My Little SERParser 3.2
- В прошлый раз немного накосячил с Гуглом: парсер зря вырезал последнюю ссылку (ранее там была пустая строка, но теперь нет). Поправил это место, теперь последний элемент вырезается только если он правда пуст.
- Вроде бы парсинг поиска по видео Гугла еще не был явным образом артикулирован. Нарочно не делал, но - работает.
My Little SERParser 3.1
- Добавлен парсинг еще одного варианта мобильной выдачи Яндекса - с чуть иной версткой.
- Добавлен костыль для дедублирования урлов, вытащенных из поиска Гугла. Не устаю удивляться странности верстки этого поисковика.
My Little SERParser 3.0
- В область срабатывания добавлен тачевый поиск. Тем более, что верстка там та же, парсится все хорошо без доработок.
- Расширение переведено на манифест версии 3.
- Как выяснилось, в старом манифесте я забыл указать ссылку на файл с данными об обновлениях, так что расширение не обновлялось автоматически. Штош, и от нового манифеста есть польза, похоже.
My Little SERParser 2.1
- Новая клевая технология перевода документов в органической выдаче Яндекса привела к тому, что ссылки на такие документы извлекаются дважды. В новой версии учтен этот нюанс, ссылки на переведенные документы более не дублируются.
My Little SERParser 2.0
- Добавлен парсер Бинга. Редко, но порой бывает нужно.
- Вымучил-таки селектор для Гугла, который не вызывает дублирование. Кажется. Положительно, выдача Гугла очень странно сверстана.
My Little SERParser 1.8
- У Яндекс.Картинок поменялась верстка немного. Поправил классы для сбора ссылок на изображения.
My Little SERParser 1.7
- Гугл снова поизвращался над версткой страницы результатов. Расширение перестало видеть урлы органики. Вот, коррекция проведена, в новой версии ссылки снова собираются.
My Little SERParser 1.6
- Расширилась область срабатывания скриптов в Гугле. Теперь сбор ссылок идет в любой доменной зоне.
My Little SERParser 1.5
- Поломался сбор урлов из Яндекс.Новостях. Поправлено.
- Часть органики поиска Яндекса могла не попадать в выдачу из-за изменений в верстке. Уточнен класс ссылки - теперь попадает все нужное.
- Также сломался сбор ссылок с Google. Починено пока, но верстка у Гугла странная, надежно сделать сложно.
- Делать отдельное расширение под Firefox надоело, отныне будет лишь версия под Chromium.
My Little SERParser 1.4
- Обнаружился недочет при парсинге на некоторых запросах: Яндекс.Новости определялись по «news» в поисковой ссылке - что, очевидно, неправильно (ежели искать в большом поиске Яндекса по слову «news» - расширение думало, что пользователь в Яндекс.Новостях, и сбор ссылок ломался). Переделал определение типа поиска, стало надежнее.
My Little SERParser 1.3
- Добавлена сборка урлов из поиска в Яндекс.Новостях.
- Уточнена область срабатывания скриптов.
My Little SERParser 1.2
- Поправлен парсинг выдачи Гугла - с некоторых пор туда попадали также ссылки на перевод документов, теперь нет.
- Небольшие корректировки области срабатывания скриптов.
My Little SERParser 1.1
- Пользовательские скрипты превращены в расширение для Chromium / Firefox. И имя ему My Little SERParser.
- У Гугла немного изменилась верстка, в связи с чем парсер стал собирать и те ссылки, которые собирать не нужно. Исправлено.
- Добавлено еще несколько урлов, на которых скрипты работать не должны.
Яндекс 4.7.1
- Минорное обновление: область работы скрипта чуть расширена, так как обнаружился еще один вариант ссылки на поисковую выдачу.
Яндекс 4.7
- Добавлено извлечение ссылок из результатов нынешней версии поиска по блогам от Яндекса.
- Починен фильтр рекламных (и иных ненужных) ссылок.
- В исключения добавлено еще несколько ссылок на страницы, где скрипт работать не должен.
Яндекс 4.6
- В связи с выходом модуля для парсинга Гугла сей модуль чуть сменил имя.
- Добавлено еще одно исключение, чтобы скрипт не запускался там, где не нужно.
- Чуть подправлены сообщения о копировании.
- Добавлены переходы (плавное изменение состояния некоторых элементов).
- В статистику добавлено выделение цветом чисел.
- При наведении на кнопку курсор теперь меняет вид, призывая всенепременно кликнуть.
- Вычисление ширины для элемента textarea теперь привязано к полю для ввода запроса, что, кажется, адекватнее и надежнее, нежели былая привязка к ширине всей поисковой шапки (там частенько чуть ли не половину занимает пустота).
Google 1.0
- Первая версия скрипта для парсинга выдачи Гугла содержит если не все, то большую часть нужных фич определенно: парсит веб, сообщает статистику, копирует собранное в буфер обмена. Вангую, что будущие обновления чаще всего будут связаны с изменениями в верстке Гугла.
Яндекс 4.5.1
- Минорное обновление: в поиске по людям чуть поменялась верстка, поэтому целевой класс в скрипте понадобилось обновить.
Яндекс 4.5
- Добавлен сбор ссылок из Яндекс.Каталога. В связи с этим чуть доработана фильтрация ссылок.
- В связи с асинхронной сущностью некоторый частей Яндекса, была проблемка с необновлением собранных ссылок при повторном запросе без полной перезагрузки страницы. Теперь скрипт следит за адресом в адресной строке браузера, и при изменениях в нем запускает себя снова. Задержка в несколько секунд сделана для того, чтобы новые результаты поиска успели подгрузиться.
- Уточнена область работы скрипта. На некоторые устаревшие поисковые урлы скрипт ранее не реагировал, теперь реагирует. Также ранее скрипт пытался собирать ссылки там, где не надо; теперь он в ненужных разделах вовсе не запускается.
Яндекс 4.4
- Скрипт теперь может работать более чем с одним классом ссылок на странице. Делалось это с определенной целью: нужно было извлекать из страницы дубликатов картинок не только ссылки на графические файлы, но и ссылки на страницы-источники картинок. Увы, в нынешней верстке в исходном коде просто нет нужных ссылок. Ну да ладно, может, в будущем понадобится.
- В связи с предыдущим пунктом немного изменен дизайн: добавлены разделители, а граница textarea теперь сплошная.
- Побежден AJAX при помощи задержки выполнения скрипта (см. Руководство пользователя).
- В связи с предыдущим пунктом сделано ограничение на высоту элемента textarea: теперь если ссылок более 50, высота остается равной 50 строкам. Копий в картинках может быть более тысячи. Подумалось, что такая простыня не очень удобна.
- С двумя кнопками я погорячился. Теперь она одна.
- Модальные окна выпилены окончательно. Теперь все сообщения - только в мягкой форме.
Яндекс 4.2
Радикальное переосмысление скрипта, он переписан почти целиком.
- Основной код перенесен в функцию.
- Добавлен кое-какой дизайн.
- Добавлена работа с поиском по людям.
- Добавлена работа с дубликатами изображений в поиске по картинкам.
- Добавлена статистика.
- Добавлены кнопки выделения и копирования.
- Добавлены сигналы об ошибках.
Яндекс 1-3
Старые версии скрипта вида со странным (впрочем, вполне рабочим) циклом и отсутствием какого-либо дружелюбия.